

22 Best DataOps Tools To Optimize Your Data Management and Observability In 2023

The data landscape is rapidly evolving, and the amount of data being produced and distributed on a daily basis is downright staggering. According to the report by Statista, currently, there are approximately 120 zettabytes of data in existence (as of 2023), and this number is projected to reach 181 zettabytes by 2025.

As the volume of data continues to expand rapidly, so does the demand for efficient data management and observability solutions and tools. The actual value of data lies in how it is being utilized. Collecting and storing data alone is not enough; it must be leveraged and used correctly to get valuable insights. These insights can range from demographics to consumer behavior and even future sales predictions, providing an unparalleled resource for business decision-making processes. Also, with real-time data, businesses can make quick and informed decisions, adapt to the market and capitalize on live opportunities. However, this is only possible if data is of good quality, outdated, misleading, or difficult to access, which is precisely where DataOps comes to the rescue and plays a crucial role in optimizing and streamlining data management processes.
Unpacking the essence of DataOps
DataOps is a set of best practices and tools that aims to enhance the collaboration, integration, and automation of data management operations and tasks. DataOps seeks to improve the quality, speed, and collaboration of data management through an integrated and process-oriented approach, utilizing automation and agile software engineering practices similar to that of DevOps to speed up and streamline the process of accurate data delivery [1]. It is designed to help businesses and organizations better manage their data pipelines, reduce the workload and time required to develop and deploy new data-driven applications and improve the quality of the data being used.
Now that we have a clear understanding of what DataOps means let's delve deeper into its key components. The key components of a DataOps strategy include data integration, data quality management and measurement, data governance, data orchestration, and DataOps Observability.
Data integration
Data integration involves integrating and testing code changes and promptly deploying them to production environments, ensuring accuracy and consistency of data as it is integrated and delivered to appropriate teams.
Data quality management
Data Quality Management involves identifying, correcting, and preventing errors or inconsistencies in data, ensuring that the data being used is highly reliable and accurate.
Data governance
Data governance ensures that data is collected, stored, and used consistently, ethically and complies with regulations.
Data orchestration
Data orchestration helps to manage and coordinates data processing in a pipeline, specifying and scheduling tasks and dealing with errors to automate and optimize data flow through the data pipeline. It is crucial for ensuring the smooth operation and performance of the data through the data pipeline.
DataOps observability
DataOps observability refers to the ability to monitor and understand the various processes and systems involved in data management, with the primary goal of ensuring the reliability, trustworthiness, and business value of the data. It involves everything from monitoring and analyzing data pipelines to maintaining data quality and proving the data's business value through financial and operational efficiency metrics. DataOps observability allows businesses and organizations to improve the efficiency of their data management processes and make better use of their data assets. It aids in ensuring that data is always correct, dependable, and easily accessible, which in turn helps businesses and organizations make data-driven decisions, optimize data-related costs/spend and generate more value from it.
Top DataOps and DataOps Observability tools to simplify data management, cost & collaboration processes
One of the most challenging aspects of DataOps is integrating data from various sources and ensuring data quality, orchestration, observability, data cost management, and governance. DataOps aims to streamline these processes and improve collaboration among teams, enabling businesses to make better data-driven decisions and achieve improved performance and results [2]. In this article, we will focus on DataOps observability and the top DataOps tools businesses can use to streamline their data management, costs, and collaboration processes.
A wide variety of DataOps tools are available on the market, and choosing the right one can be a very daunting task. To help businesses make an informed decision, this article has compiled a list of the top DataOps tools that can be used to manage data-driven processes.
Data Integration Tools
1) Fivetran
Fivetran is a very popular and widely adopted data integration platform that simplifies the process of connecting various data sources to a centralized data warehouse [3]. This enables users or businesses to easily analyze and visualize their data in one place, eliminating the need to manually extract, transform, and load (ETL) data from multiple different sources.
Fivetran provides sets of pre-built connectors for a wide range of data sources, including popular databases, cloud applications, SaaS applications—and even flat files. These connectors automate the process of data extraction, ensuring that the data is always up-to-date, fresh and accurate. Once data is in the central data warehouse, Fivetran performs schema discovery and data validation, automatically creating tables and columns in the data warehouse based on the structure of the data source, making it really very easy to set up and maintain data pipelines without the need for manually writing custom code.
Fivetran also offers features like data deduplication, incremental data updates, and real-time data replication. These features help make sure that the data is always complete, fresh and accurate.

Talend Data Fabric solution is designed to help businesses and organizations make sure they have healthy data to stay in control, mitigate risk, and drive massive value. The platform combines data integration, integrity, and governance to deliver reliable data that businesses and organizations can rely on for decision-making processes. Talend helps businesses build customer loyalty, improve operational efficiency and modernize their IT infrastructure.
Talend's unique approach to data integration makes it easy for businesses and organizations to bring data together from multiple sources and power all their business decisions. It can integrate virtually any data type from any data source to any data destination(on-premises or in the cloud). The platform is flexible, allowing businesses and organizations to build data pipelines once and run them anywhere, with no vendor or platform lock-in. And the solution is an all-in-one (unified solution), bringing together data integration, data quality, and data sharing on an easy-to-use platform.
Talend's Data Fabric offers a multitude of best-in-class data integration capabilities, such as Data Integration, Pipeline Designer, Data Inventory, Data Preparation, Change Data Capture, and Data Stitching. These tools make data integration, data discovery/search and data sharing more manageable, enabling users to prepare and integrate data quickly, visualize it, keep it fresh, and move it securely.

3) StreamSets
StreamSets is a powerful data integration platform that allows businesses to control and manage data flow from a variety of batch and streaming sources to modern analytics platforms. You can deploy and scale your dataflows on-edge, on-premises, or in the cloud using its collaborative, visual pipeline design, while also mapping and monitoring them for end-to-end visibility[4]. The platform also allows for the enforcement of Data SLAs for high availability, quality, and privacy. StreamSets enables businesses and organizations to quickly launch projects by eliminating the need for specialized coding skills through its visual pipeline design, testing, and deployment features, all of which are accessible via an intuitive graphical user interface. With StreamSets, brittle pipelines and lost data will no longer be a concern, as the platform can automatically handle unexpected changes. The platform also includes a live map with metrics, alerting, and drill-down functionality, allowing businesses to efficiently integrate data in a breeze.

4) K2View
K2View provides enterprise-level DataOps tools. It offers a data fabric platform for real-time data integration, which enables businesses and organizations to deliver personalized experiences [6]. K2View's enterprise-level data integration tools integrate data from any kind of source and make it accessible to any consumer through various methods such as bulk ETL, reverse ETL, data streaming, data virtualization, log-based CDC, message-based integration, SQL—and APIs.
K2View can ingest data from various sources and systems, enhance it with real-time insights, convert it into its patented micro-database, and ensure performance, scalability, and security by compressing and encrypting the micro-database individually. It then applies data masking, transformation, enrichment, and orchestration tools on-the-fly to make the data accessible to authorized consumers in any format while adhering to data privacy and security rules.

5) Alteryx
Alteryx is a very powerful data integration platform that allows users to easily access, manipulate, analyze, and output data. The platform utilizes a drag-and-drop interface (low code/no code interface) and includes a variety of tools and connectors(80+) for data blending, predictive analytics, and data visualization[7]. It can be used in a one-off manner or, more commonly, as a recurring process called a "workflow." The way Alteryx builds workflows also serves as a form of process documentation, allowing users to view, collaborate, support and enhance the process. The platform can read and write data to files, databases, and APIs, and it also includes functionality for predictive analytics and geospatial analysis. Alteryx is currently being used in a variety of industries and functional areas and can be used to more quickly and efficiently automate data integration processes. Some common use cases include combining and manipulating data within spreadsheets, supplementing SQL development, APIs, cloud or hybrid access, data science, geospatial analysis—and creating reports and dashboards.
Note: Alteryx is often compared to ETL tools, but it is important to remember that its primary audience is data analysts. Alteryx aims to empower business users by giving them the freedom to access, manipulate, and analyze data without relying on IT.

Data Quality Testing and Monitoring Tools
1) Monte Carlo
Monte Carlo is a leading enterprise data monitoring and observability platform. It provides an end-to-end solution for monitoring and alerting for data issues across the data warehouses, data lakes, ETL, and business intelligence platforms. It uses machine learning and AI to learn about the data and proactively identify data-related issues, assess their impact, and notify those who need to know. The platform's automatic and immediate identification of the root cause of issues allows teams to collaborate and resolve problems faster, and it also provides automatic, field-level lineage , data discovery, and centralized data cataloging that allows teams to better understand the accessibility, location, health, and ownership of their data assets. The platform is designed with security in mind, scales accordingly with the provided stack, and includes a no-code or low-code(code-free) onboarding feature for easy implementation with the existing data stack.

2) Databand
Databand is a data monitoring and observability platform recently acquired by IBM that helps organizations detect and resolve data issues before they impact the business. It provides a fierce, end-to-end view of data pipelines, starting with source data, which allows businesses and organizations to detect and resolve issues early, reducing the mean time to detection (MTTD) and mean time to resolution (MTTR) from days and weeks to minutes.
One key features of Databand is its ability to automatically collect metadata from modern data stacks such as Airflow, Spark, Databricks, Redshift, dbt, and Snowflake. This metadata is used to build historical baselines of common data pipeline behavior, which allows organizations to get visibility into every data flow from source to destination.
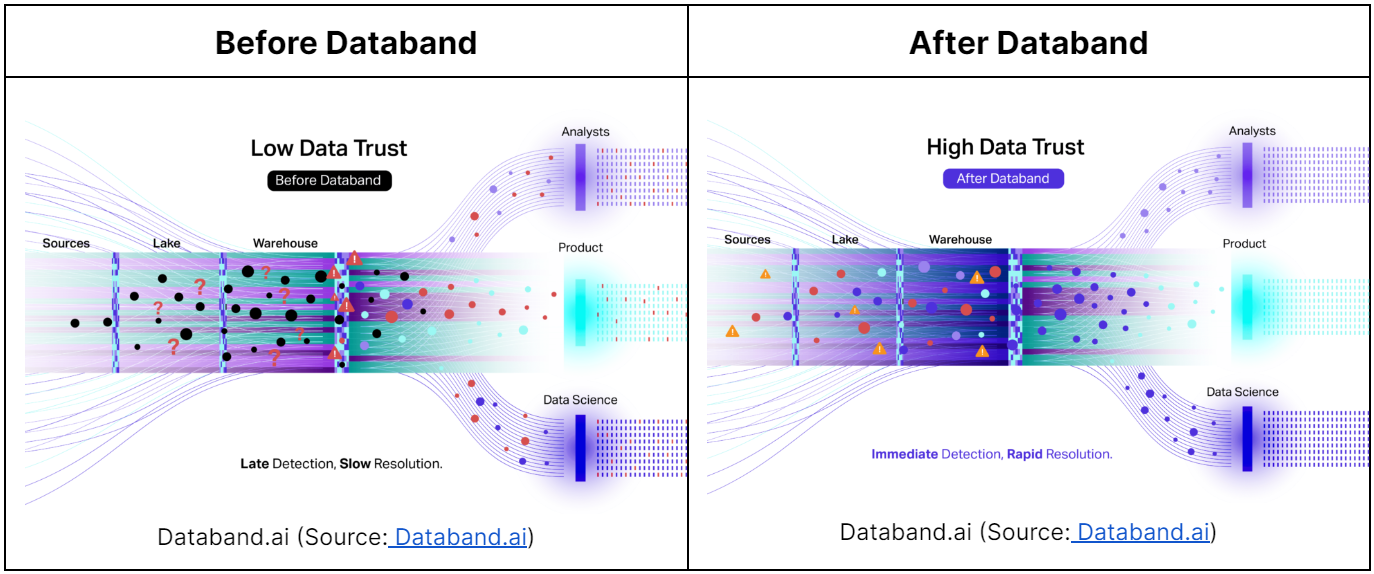
Databand also provides incident management, end-to-end lineage, data reliability monitoring, data quality metrics, anomaly detection, and DataOps alerting and routing capabilities. With this, businesses and organizations can improve data reliability and quality and visualize how data incidents impact upstream and downstream components of the data stack. Databand's combined capabilities provide a single solution for all data incidents, allowing engineers to focus on building their modern data stack rather than fixing it.
3) Data Fold
Datafold is a data reliability platform focused on proactive data quality management that helps businesses prevent data catastrophes. It has the unique ability to detect, evaluate, and investigate data quality problems before they impact productivity. The platform offers real-time monitoring to identify issues quickly and prevent them from becoming data catastrophes.

Datafold harnesses the power of machine learning with AI to provide analytics with real-time insights, allowing data engineers to make top-quality predictions from large amounts of data.
Some of the key features of Datafold include:
One-Click Regression Testing for ETL
Data flow visibility Across all pipelines and BI reports
SQL Query Conversion, Data Discovery, and Multiple data source Integrations
Datafold offers a simple yet intuitive user interface(UI) and navigation with powerful features. The platform allows deep exploration of how tables and data assets relate. The visualizations are really very easy to understand. Data quality monitoring is also super flexible. However, the data integrations they support are relatively limited.
4) Query Surge
QuerySurge is a very powerful/versatile tool for automating data quality testing and monitoring, particularly for big data, data warehouses, BI reports, and enterprise-level applications. It is particularly designed to integrate seamlessly, allowing for continuous testing and validation of data as it flows.
Query Surge also provides the ability to create and run tests without needing to write SQL through smart query wizards. This allows for column, table, and row-level comparisons and automatic column matching. Also, users can create custom tests that can be modularized with reusable "snippets" of code, set thresholds, check data types, and perform other advanced number of validation checks. QuerySurge also has robust scheduling capabilities, allowing users to run tests pronto, at a specified date and time. On top of that, it also supports 200+ supported vendors and tech stacks, so it can test across a wide variety of platforms, including big data lakes, data warehouses, traditional databases, NoSQL document stores, BI reports, flat files, JSON files—and a whole lot more.

One key benefits of QuerySurge is its ability to integrate with other solutions in the DataOps pipeline, such as data integration/ETL solutions, build/configuration solutions, QA and test management solutions. The tool also includes a Data Analytics Dashboard, which allows users to monitor test execution progress in real-time, drill down into data to examine results, and see stats for executed tests. It also has an out-of-the-box integration with plethora of services and any other solution with API access.
QuerySurge is available both on-premises and in the cloud, with support for AES 256-bit encryption, LDAP/LDAPS, TLS, HTTPS/SSL, auto-timeout, and other security features. In a nutshell, QuerySurge is a very powerful and comprehensive solution for automating data monitoring and testing, allowing businesses and organizations to improve their data quality at speed and reduce the risk of data-related issues in the delivery pipeline.
5) Right Data
Right Data's RDT is a powerful data testing and monitoring platform that helps businesses and organizations improve the reliability and trust of their data by providing an easy-to-use interface for data testing, reconciliation, and validation. It allows users to quickly identify issues related to data consistency, quality, and completeness. It also provides an efficient way to analyze, design, build, execute and automate reconciliation and validation scenarios with little to no coding required, which helps save time and resources.

Key features of RDT:
Ability to analyze DB: It provides a full set of applications to analyze the source and target datasets. Its top-of-the-line Query Builder and Data Profiling features help users understand and analyze the data before they use the corresponding datasets in different scenarios.
Support of a wide range of data sources: RDT supports a wide range of data sources such as ODBC or JDBC, flat files, cloud technologies, SAP, big data, BI reporting—and various other sources. This allows businesses and organizations to easily connect to and work with their existing data source.
Data reconciliation: RDT has features like "Compare Row Counts" that let users compare the number of rows in the source dataset and the target dataset and find tables where the number of rows doesn't match. It also provides a "row-level data compare" feature that compares datasets between source/target and identifies rows that do not match each other.
Data Validation: RDT provides a user-friendly interface for creating validation scenarios, which enables users to establish one or more validation rules for target data sets, identify exceptions, and analyze and report on the results.
Admin & CMS: RDT has an admin console that allows the admin to manage and config the features of the tool. The console provides the ability to create + manage users, roles, and the mapping of roles to specific users. Administrators can also create, manage, and test connection profiles, which are used to create queries. The tool also provides a Content Management Studio (CMS) that enables exporting of queries, scenarios, and connection profiles from one RightData instance to another. This feature is useful for copying within the same instance from one folder to another and also for switching over the connection profile of queries.
DataOps Observability and Augmented FinOps
1) Chaos Genius
Chaos Genius is a powerful DataOps Observability tool that uses ML and AI to provide precise cost projections and enhanced metrics for monitoring and analyzing data and business metrics. One of the main reasons the tool was built was to provide value to businesses by offering a powerful, first-in-class DataOps observability tool that can help monitor and analyze data, lower spending, and improve business metrics. The tool utilizes machine learning and artificial intelligence (ML/AI) to sift through data and provide more precise cost projections and enhanced metrics.

Chaos Genius currently offers a service called "Snowflake Observability" as one of its main services.

Key features of Chaos Genius (Snowflake Observability) include:
Cost optimization and monitoring: Chaos Genius is designed to help businesses and organizations optimize and monitor the cost of a Snowflake cloud data platform. This includes finding places where costs can be cut and making suggestions for how to do so.
Enhanced query performance: Chaos Genius can analyze query patterns to identify inefficient queries and make smart recommendations to improve their performance, which can lead to faster and more efficient data retrieval and improve the overall performance of the data warehouse.
Reduced Spendings: Chaos Genius enables businesses to better enhance the efficiency of their systems and reduce total spending by about ~10% - 30%.
Affordability: Chaos Genius offers an affordable pricing model with three tiers. The first tier is completely free, while the other two are business-oriented plans for companies that want to monitor more metrics. This makes it accessible to businesses of all sizes and budgets.
2) Unravel
Unravel is a DataOps observability platform that provides businesses and organizations with a thorough view of their entire data stack and helps them optimize performance, automate troubleshooting, and manage and monitor the cost of their entire data pipelines. The platform is also designed to work with different cloud service providers, for example, Azure, Amazon EMR, GCP, Cloudera and even on-premises environments, providing businesses with the flexibility to manage their data pipeline regardless of where their data resides.

Unravel uses the power of machine learning and AI to model data pipelines from end to end, providing businesses with a detailed understanding of how data flows through their systems. This enables businesses/organizations to identify bottlenecks, optimize resource allocation and improve the overall performance of their data pipelines.
The platform's data model enables businesses to explore, correlate, and analyze data across their entire environment, providing deep insights into how apps, services, and resources are used and what works and what doesn't, allowing businesses to quickly identify potential issues and take immediate action to resolve them. Not only that, but Unravel also has automatic troubleshooting features that can help businesses find the cause of a problem quickly and take steps to fix it, saving them a huge amount of spending and making their data pipelines more reliable and efficient.
Data Orchestration Tools
Apache Airflow is a fully open source DataOps workflow orchestration tool to author, schedule, and monitor workflows programmatically. Airbnb first developed it, but now it is under the Apache Software Foundation [8]. It is a tool for expressing and managing data pipelines and is often used in data engineering. It allows users to define, schedule, and monitor workflows as directed acyclic graphs (DAGs) of tasks. Airflow provides a simple and powerful way to manage data pipelines, and it is simple to use, allowing users to create and manage complex workflows quickly; on top of that, it has a large and active community that provides many plugins, connectors, and integrations with other tools that makes it very versatile.

Key features of Airflow include:
Dynamic pipeline generation: Airflow's dynamic pipeline generation is one of its key features. Airflow allows you to define and generate pipelines programmatically rather than manually creating and managing them. This facilitates the creation and modification of complex workflows.
Extensibility: Airflow allows using custom plugins, operators and executors, which means you can add new functionality to the platform to suit your specific needs and requirements; this makes Airflow highly extensible and an excellent choice for businesses and organizations with unique requirements or working with complex data pipelines.
Scalability: Airflow has built-in support for scaling thousands of tasks, making it very well-suited for large-scale organizations or running large-scale data processing tasks.
2) Shipyard
Shipyard is a powerful data orchestration tool designed to help data teams streamline and simplify their workflows and deliver data at very high speed. The tool is intended to be code-agnostic, allowing teams to deploy code in any language they prefer without the need for a steep learning curve. It is cloud-ready, meaning it eliminates the need for teams to spend hours and hours spinning up and managing their servers. Instead, they can orchestrate their workflows in the cloud, allowing them to focus on what they do best—working with data. Shipyard can also run thousands of jobs at once, making it ideal for scaling data processing tasks. The tool can dynamically scale to meet the demand, ensuring that workflows run smoothly and efficiently even when dealing with large amounts of data.

Shipyard comes with a very intuitive visual UI, allowing users to construct workflows directly from the interface and make changes as needed by dragging and dropping. The advanced scheduling, webhooks and on-demand triggers make automating workflows on any schedule easy. It also allows for cross-functional workflows, meaning that the entire data process can be interconnected across the entire data lifecycle, helping teams keep track of the entire data journey, from data collection and processing to visualization and analysis.
Shipyard also provides instant notifications, which help teams catch and fix critical breakages before anyone even notices. It also has automatic retries and cutoffs, which give workflows resilience, so teams don't have to lift a finger. Not only that, it can isolate and address the root cause in real time, so teams can get back up and running in seconds. Also, it allows teams to connect their entire data stack in minutes, seamlessly moving data between the existing tools in the data stack, regardless of the cloud provider. With over 20+ integrations and 60+ low-code templates to choose from, data teams can begin connecting their existing tools in record speeed!!!
3) Dagster
Dagster is a next-generation open source data orchestration platform for developing, producing, and observing data assets in real-time. Its primary focus is to provide a unified experience for data engineers, data scientists, and developers to manage the entire lifecycle of data assets, from development and testing to production and monitoring. Using Dagster, users can manage their data assets with code and monitor "runs" across all jobs in one place with the run timeline view. On the other hand, the run details view allows users to zoom into a run and pin down issues with surgical precision.
Dagster also allows users to see each asset's context and update it all in one place, including materializations, lineage, schema, schedule, partitions—and a whole lot more. Not only that, but it also allows users to launch and monitor backfills over every partition of data. Dagster is an enterprise-level orchestration platform that prioritizes developer experience(DX) with fully serverless + hybrid deployments, native branching, and provides out-of-the-box CI/CD configuration.

4) AWS glue
AWS Glue is a data orchestration tool that makes it easy to discover, prepare, and combine data for analytics and machine learning workflows. With Glue, you can crawl data sources, extract, transform and load (ETL) data, and create/schedule data pipelines using a simple visual UI interface. Glue can also be used for analytics and includes tools for authoring, running jobs, and implementing business workflows. AWS Glue offers data discovery, ETL, cleansing, and central cataloging and allows you to connect to over 70 diverse data sources [9]. You can create, run and monitor ETL pipelines to load data into data lakes and query cataloged data using Amazon Athena, Amazon EMR, and Redshift Spectrum. It is serverless in nature, meaning there's no infrastructure to manage, and it supports all kinds of workloads like ETL, ELT, and streaming all packaged in one service. AWS Glue is very user-friendly and is suitable for all kinds of users, including developers and business users. Its ability to scale on demand allows users to focus on high-value activities that extract maximum value from their data; it can handle any data size and support all types of data and schema variations.

AWS Glue provides TONS of awesome features that can be used in a DataOps workflow, such as:
Data Catalog: A central repository to store structural and operational metadata for all data assets.
ETL Jobs: The ability to define, schedule, and run ETL jobs to prepare data for analytics.
Data Crawlers: Automated data discovery and classification that can connect to data sources, extract metadata, and create table definitions in the Data Catalog.
Data Classifiers: The ability to recognize and classify specific types of data, such as JSON, CSV, and Parquet.
Data Wrangler: A visual data transformation tool that makes it easy to clean and prepare data for analytics.
Security: Integrations with AWS Identity and Access Management (IAM) and Amazon Virtual Private Cloud (VPC) to help secure data in transit and at rest.
Scalability: The ability to handle petabyte-scale data and thousands of concurrent ETL jobs.
Data Governance Tools
1) Collibra
Collibra is an enterprise-oriented data governance tool that helps businesses and organizations understand and manage their data assets. It enables businesses and organizations to create an inventory of data assets, capture metadata about 'em, and govern these assets to ensure regulatory compliance. The tool is primarily used by IT, data owners, and administrators who are in charge of data protection and compliance to inventory and track how data is used. Collibra's main aim is to protect data, ensure it is appropriately governed and used, and eliminate potential fines and risks from a lack of regulatory compliance.

Collibra offers six key functional areas to aid in data governance:
Collibra Data Quality & Observability: Monitors data quality and pipeline reliability to aid in remedying anomalies.
Collibra Data Catalog: A single solution for finding and understanding data from various sources.
Data Governance: A location for finding, understanding, and creating a shared language around data for all individuals within an organization.
Data Lineage: Automatically maps relationships between systems, applications, and reports to provide a comprehensive view of data across the enterprise.
Collibra Protect: Allows for the discovery, definition, and protection of data from a unified platform.
Data Privacy: Centralizes, automates, and guides workflows to encourage collaboration and address global regulatory requirements for data privacy.
2) Alation
Alation is an enterprise-level data catalog tool that serves as a single reference point for all of an organization's data. It automatically crawls and indexes over 60 different data sources, including on-premises databases, cloud storage, file systems, and BI tools. Using query log ingestion, Alation parses queries to identify the most frequently used data and the individuals who use it the most, forming the basis of the catalog. Users can then collaborate and provide context for the data. With the catalog in place, data analysts and scientists can quickly and easily locate, examine, verify, and reuse data, hence boosting their productivity. Alation can also be used for data governance, allowing analytics teams to efficiently manage and enforce policies for data consumers.

Key benefits of using Alation:
Boost analyst productivity
Improve data comprehension
Foster collaboration
Minimize the risk of data misuse
Eliminate IT bottlenecks
Easily expose and interpret data policies
Alation offers various solutions to improve productivity, accuracy and data-driven decision-making. These include:
Alation Data Catalog: Improves the efficiency of analysts and the accuracy of analytics, empowering all members of an organization to find, understand, and govern data efficiently.
Alation Connectors: A wide range of native data sources that speed up the process of gaining insights and enable data intelligence throughout the enterprise. (Additional data sources can also be connected with the Open Connector Framework SDK.)
Alation Platform: An open and intelligent solution for various metadata management applications, including search and discovery, data governance, and digital transformation.
Alation Data Governance App: Simplifies secure access to the best data in hybrid and multi-cloud environments.
Alation Cloud Service: Offers businesses and organizations the option to manage their data catalog on their own or have it managed for them in the cloud.
Data Cloud and Data Lake Platforms
1). Databricks
Databricks is a cloud-based lakehouse platform founded in 2013 by the creators of Apache Spark, Delta Lake, and MlFlow [10]. It unifies data warehousing and data lakes to provide an open and unified platform for data and AI. The Databricks Lakehouse architecture is designed to manage all data types and is cloud-agnostic, allowing data to be governed wherever it is stored. Teams can collaborate and access all the data they need to innovate and improve. The platform includes the reliability and performance of Delta Lake as the data lake foundation, fine-grained governance and support for persona-based use cases. It also provides instant and serverless compute, managed by Databricks. The Lakehouse platform eliminates the challenges caused by traditional data environments such as data silos and complicated data structures. It is simple, open, multi-cloud, and supports various data team workloads. The platform allows for flexibility with existing infrastructure, open source projects, and the Databricks partner network.

2) Snowflake
Snowflake is a cloud data platform offering a software-as-a-service model fo storing and analyzing LARGE amounts of data. It is designed to support high levels of concurrency, scalability and performance. It allows customers to focus on getting value from their data rather than managing the infrastructure on which it's stored. The company was founded in 2012 by three experts, Benoit Dashville, Thierry Cruanes, and Marcin Zukowski [11]. Snowflake runs on top of cloud infrastructure, such as AWS, Microsoft Azure, and Google's cloud platforms. It allows customers to store and analyze their data using the elasticity of the cloud, providing speed, ease of use, cost-effectiveness, and scalability. It is widely used for data warehousing, data lakes, and data engineering. It is designed to handle the complexities of modern data management processes. Not only that, but it also supports various data analytics applications, such as BI tools, ML/AI, and data science. Snowflake also revolutionized the pricing model by utilizing a "utilization model" that focuses on a client's consumption based on whether they're computing or storing data, making everything more flexible and elastic.

Key features of Snowflake include:
Scalability: Snowflake offers scalability through its multi-cluster shared data architecture, allowing for easy scaling up and down of resources as needed.
Cloud-Agnostic: Snowflake is available on all major cloud providers (AWS, GCP, AZURE) while maintaining the same user experience, allowing for easy integration with current cloud architecture.
Auto-scaling + Auto-Suspend: Snowflake automatically starts and stops clusters during resource-intensive processing and stops virtual warehouses when idle for cost and performance optimization.
Concurrency and Workload Separation: Snowflake's multi-cluster architecture separates workloads to eliminate concurrency issues and ensures that queries from one virtual warehouse will not affect another.
Zero Hardware + Software config: Snowflake does not require software installation or hardware config or commissioning, making it easy to set up and manage.
Semi-Structured Data: Snowflake's architecture allows for the storage of structured and semi-structured data through the use of VARIANT data types.
Security: Snowflake offers a wide range of security features, including network policies, authentication methods and access controls, to ensure secure data access and storage.
Google BigQuery is a fully-managed and serverless data warehouse provided by Google Cloud that helps organizations manage and analyze large amounts of data with built-in features such as machine learning, geospatial analysis, and business intelligence[12]. It allows businesses and organizations to easily store, ingest, store, analyze, and visualize large amounts of data. Bigquery is designed to handle up to petabyte-scale data and supports SQL queries for data analysis purposes. The platform also includes BigQuery ML, which allows businesses or users to train and execute machine learning models using their enterprise data without needing to move it around.

BigQuery integrates with various business intelligence tools and can be easily accessed through the cloud console, a command-line tool, and even APIs. It is also directly integrated with Google Cloud’s Identity and Access Management Service so that one can securely share data and analytics insights across organizations. With BigQuery, businesses only have to pay for data storing, querying, and streaming inserts. Loading and exporting data are absolutely free of charge.
Amazon Redshift is a cloud-based data warehouse service that allows for the storage and analysis of large data sets. It is also useful for migrating LARGE databases. The service is fully managed and offers scalability and cost-effectiveness for storing and analyzing large amounts of data. It utilizes SQL to analyze structured and semi-structured data from a variety of sources, including data warehouses, operational databases, and data lakes, which are enabled by AWS-designed hardware and powered by AI & machine learning; due to this, it is able to deliver optimal cost-performance at any scale. The service also offers high-speed performance and efficient querying capabilities to assist in making business decisions.

Key features of Amazon Redshift include:
High Scalability: Redshift allows users to start with a very small amount of data and scale up to a petabyte or more as their data grows incrementally.
Query execution + Performance: Redshift uses columnar storage, advanced compression, and parallel query execution to deliver fast query performance on large data sets.
Pay-as-you-go pricing model: Redshift uses a pay-as-you-go pricing model and allows users to choose from a range of node types and sizes to optimize cost and performance.
Robust Security: Redshift integrates with AWS security services like AWS Identity and Access Management (IAM) and Amazon Virtual Private Cloud (VPC)—and more(learn more from here)—to keep data safe.
Integration: Redshift can be easily integrated with varios other services such as Datacoral, Etleap, Fivetran, SnapLogic,Stitch,Upsolver,Matillion—and more.
Monitoring + Management tools: Redshift has various management and monitoring tools, including the Redshift Management Console and Redshift Query Performance Insights, to help users manage and monitor their clusters in their data warehouse.
Conclusion
As the amount of data continues to grow at an unprecedented rate, the need for efficient data management and observability solutions has never been greater. But simply collecting and storing data won't cut it—it's the insights and value it can provide that truly matter. However, this can only be achieved if the data is high quality, up-to-date, and easily accessible. This is exactly where DataOps comes in—providing a powerful set of best practices and tools to improve collaboration, integration, and automation, allowing businesses to streamline their data pipelines, reduce costs and workload, and enhance data quality. Hence, by utilizing the tools mentioned above, businesses can minimize data-related expenses and extract maximum value from their data.
Don't let your data go to waste—harness its power with DataOps.
References
[1]. A. Dyck, R. Penners and H. Lichter, "Towards Definitions for Release Engineering and DevOps," 2015 IEEE/ACM 3rd International Workshop on Release Engineering, Florence, Italy, 2015, pp. 3-3, doi: 10.1109/RELENG.2015.10.
[2] Doyle, Kerry. “DataOps vs. MLOps: Streamline your data operations.” TechTarget, 15 February 2022, https://www.techtarget.com/searchitoperations/tip/DataOps-vs-MLOps-Streamline-your-data-operations. Accessed 12 January 2023.
[3] Danise, Amy, and Bruce Rogers. “Fivetran Innovates Data Integration Tools Market.” Forbes, 11 January 2022, https://www.forbes.com/sites/brucerogers/2022/01/11/fivetran-innovates-data-integration-tools-market/. Accessed 13 January 2023.
[4] Basu, Kirit. “What Is StreamSets? Data Engineering for DataOps.” StreamSets, 5 October 2015, https://streamsets.com/blog/what-is-streamsets/. Accessed 13 January 2023.
[5] Chand, Swatee. “What is Talend | Introduction to Talend ETL Tool.” Edureka, 29 November 2021, https://www.edureka.co/blog/what-is-talend-tool/#WhatIsTalend. Accessed 12 January 2023.
[6] “Delivering real-time data products to accelerate digital business [white paper].” K2View, https://www.k2view.com/hubfs/K2View%20Overview%202022.pdf. Accessed 13 January 2023.
[7] “Complete introduction to Alteryx.” GeeksforGeeks, 3 June 2022, https://www.geeksforgeeks.org/complete-introduction-to-alteryx/. Accessed 13 January 2023.
[8] “Apache Airflow: Use Cases, Architecture, and Best Practices.” Run:AI, https://www.run.ai/guides/machine-learning-operations/apache-airflow. Accessed 12 January 2023.
[9] “What is AWS Glue? - AWS Glue.” AWS Documentation, https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html. Accessed 13 January 2023.
[10] “About Databricks, founded by the original creators of Apache Spark™.” Databricks, https://www.databricks.com/company/about-us. Accessed 18 January 2023.
[11] “You're never too old to excel: How Snowflake thrives with 'dinosaur' cofounders and a 60-year-old CEO.” LinkedIn, 4 September 2019, https://www.linkedin.com/pulse/youre-never-too-old-excel-how-snowflake-thrives-dinosaur-anders/. Accessed 18 January 2023.
[12] “What is BigQuery?” Google Cloud, https://cloud.google.com/bigquery/docs/introduction. Accessed 18 January 2023.


