

DataOps 101: An Introduction to the Essential Approach of Data Management Operations and Observability

In today's day and age, data has become a crucial asset for organizations across all kinds of industries. Industry after industry—from retail to e-commerce to manufacturing to accounting to insurance to healthcare to finance—uses data to fuel innovation, enhance operations, and make informed decisions. However, managing and utilizing data effectively is no easy task. That is exactly where the field of “DataOps” comes in. DataOps borrows concepts from DevOps and attempts to help organizations rapidly deliver the right data at a very fast pace. The traditional process for delivering data to the business can be really very slow and really time-consuming; therefore, DataOps aims to promote agility, flexibility, and the continuous delivery of fresh data.
In this article, we'll provide a comprehensive introduction and guide to DataOps, covering its essential key components, the benefits it offers, how it differs from DevOps and the best practices for implementing it. We'll also go over some of the potential challenges in implementing DataOps and provide resources for further reading on this vital data management operations strategy.
But first, let's define DataOps and explain why it's become such a crucial part of modern data management.
What is DataOps?
Data Operations, or DataOps for short, is used to describe a set of practices and processes that are designed to improve the collaboration, integration, and automation of data management operations and tasks [1]. These practices and processes include a focus on agile methodologies. It is intended to help organizations better manage their data pipelines, reduce the workload and time required to develop and deploy new data-driven applications and improve the quality of the data being used. DataOps is meant to eliminate barriers between data engineers, data scientists and data/business analysts—as well as other teams and departments within an organization—enabling them to work together more efficiently and effectively to manage and analyze data.
Many businesses and organizations have already adopted DataOps principles to make better use of their data and increase productivity [2]. Let's take a look at "Netflix" as an example; they have a large and very complex data environment, with data coming from multiple different sources, including subscriber accounts, viewing or streaming activity, and customer support inquiries. To manage this data effectively, Netflix has implemented DataOps practices and tools, such as automation, collaboration, and monitoring. Netflix has automated the data ingestion, automation and preparation processes, allowing it to quickly and accurately integrate data from multiple different sources and prepare it for analysis, which will help Netflix directly gain a better understanding of subscriber activity, behaviour and preferences, which in turn allows it to make better decisions about content/movie/show recommendations, their own marketing campaigns, and product development.
Why is DataOps important?
In today's fast-paced modern business world, DataOps plays a vital role in helping businesses and organizations stay ahead, as the ability to analyze data rapidly and precisely can provide them with a competitive advantage over others. DataOps simplifies and automates the complex process of collecting, storing, and analyzing data, making it more efficient, accurate, and relevant to the business's needs/requirements. This enables businesses to make better use of their data assets and derive more value from them. Overall, DataOps plays a key part in any organization's data management and data management operations strategy because it lets them use their fresh data assets to drive business growth and fresh new innovations.
DataOps empowers businesses and organizations to make better, faster decisions and get the most out of their data. It helps them extract valuable insights—and drive productivity as a result. With the right tools and a well-thought-out plan, (businesses) can make more informed timely decisions.[3] Nevertheless, a significant obstacle to data-driven initiatives is ensuring decision-makers have access to important data and know how to use it effectively[4]. DataOps helps bridge this gap and fosters collaboration between teams, thereby enabling organizations to deliver products faster and more effectively.
DataOps is a people-driven practice, meaning that it depends on the abilities and knowledge of the individuals. It is not a tool or application that can be bought and implemented without the required human resources. Instead, it necessitates a team of proficient data experts that can collaborate effectively and efficiently [7].
Exploring the Key Differences Between DevOps and DataOps
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) to reduce system and application development lifecycles. DevOps has been defined as an organizational approach aimed at creating empathy and cross-functional collaboration [5]. It aims to establish an environment in which software development, building, testing, and release can occur more quickly, frequently, and consistently.

The main goal of DevOps is to improve the collaboration and communication between developers and operations teams and automate the build, test, and release service cycle and manage and monitor infrastructure and applications in production.
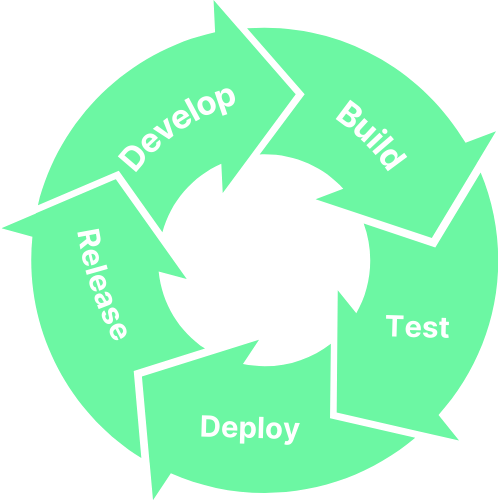
DevOps Lifecycle
DevOps lifecycle consists of several phases that are followed when developing and maintaining software applications.
Plan: The plan phase involves identifying the goals/objectives of the project and the resources that will be required to complete it.
Develop: Develop phase where the software is actually developed. This involves writing code, building mockups/prototypes, and testing the software to ensure it is functional.
Test: The test phase comes after the software has been developed; it must be tested to ensure it is error-free and will function as intended. This may include unit testing, integration testing—and other types of testing.
Deploy: Deploy phase is where the software or application is deployed to a production environment where end users can use it.
Maintain: Maintain phase is where the software will be maintained to guarantee it continues to work as expected. This could involve patch fixes, security upgrades and hotfixes to ensure the software runs smoothly indefinitely.

DataOps Lifecycle
The DataOps lifecycle typically consists of the following stages:
Ingest: Ingest stage involves extracting data from multiple different raw data sources and storing it in a centralized location, such as a data warehouse or data lake.
Prepare: Prepare stage is where data engineers and data scientists prepare the data for analysis by extracting, cleaning, and transforming it. This may involve tasks such as data deduplication, data integration/mining and feature extraction.
Model: The model **stage involves building AI/ML models and other statistical models to analyze and make predictions based on the data. Data scientists are typically responsible for this stage.
Visualize: Visualize stage involves creating charts, graphs and other visualizations to help others understand and interpret the data.
Deploy: Deploy stage is where the models and other data products developed in previous stages are deployed and made available to end users.
Observability: The observability stage involves monitoring and analyzing the performance of the data quality and ensuring that it meets the needs of the end users. This stage also involves collecting feedback and implementing improvements as needed.

To sum up, now that you know what sets the DataOps and DevOps lifecycles apart, DataOps seeks to optimize an organization's whole data lifecycle, from data ingestion and preparation through analysis and visualization. In contrast, DevOps is focused on enhancing the agility of the software development process through automation and integration. DataOps aims to improve the efficiency and effectiveness of data processing and utilization. It can be thought of as the function within an organization that controls the data journey from source to value[6].
Collaboration Across Teams for Data Delivery
DataOps is a collaborative effort within an organization, with many different teams of people working together to ensure that DataOps functions properly and delivers data value [3]. So, before the data is delivered to end users, it is subjected to a number of treatments and refinements from multiple teams. Data scientists first use their data science techniques, such as machine learning and deep learning to build models using software stacks such as Python or R and tools such as Spark or Tensorflow, among others, and the models are then transferred to data engineers, who collect and manage the data used to train and evaluate these models, while data developers and data architects create complete applications that include the models. The data governance team then implements data access controls for training and benchmarking purposes, while the operations team ( "Ops") is in charge of putting everything together and making it available to end users.
Key Components of DataOps
DataOps involves several key components which work together to improve data management processes. These includes:
Continuous integration and Continuous delivery (CI/CD)
Continuous integration and Continuous delivery (CI/CD) is a practice that involves frequently integrating and testing code changes and then quickly and efficiently pushing those changes to production environments. In DataOps, CI/CD plays a crucial role in ensuring the accuracy and consistency of data as it is integrated and delivered to the appropriate people/systems. By constantly developing, building, automating and testing data changes and then quickly delivering them to production without any downtime, DataOps teams can minimize the risk of errors and ensure that data is delivered in a timely and reliable manner.
Data governance
The process of establishing policies, procedures, and standards for managing data assets, as well as an organizational structure to support enterprise data management, is known as data governance. Data governance in DataOps helps to ensure that data is collected, stored and used in a consistent and in ethical manner.
Data quality management and measurement
Data quality management and measurement involve identifying, correcting, and preventing any errors or inconsistencies in data. It helps ensure that the data being used is fully reliable—and accurate. This is critical because poor data quality can lead to incorrect or misleading insights and decisions, which can have serious consequences.

Data Orchestration
Data orchestration refers to the management and coordination of data processing tasks in a data pipeline. It involves specifying and scheduling how tasks will be completed, as well as dealing with errors and how tasks interact with one another. Data orchestration is critical in DataOps for automating and optimizing the flow of data through the pipeline. This can include tasks such as extracting data from various sources, transforming and cleaning the data, and loading it into a target system for analysis or reporting purposes.

DataOps Observability
As we’ve already discussed what DataOps is, let’s briefly review it. DataOps is a collection of best practices and technology used to manage and develop data products, optimize data management processes, improve quality, speed, and collaboration and promote continuous improvement. DataOps is based on the same principles and practices as DevOps. Still, it has taken longer to become fully matured because data is constantly changing and can be more fragile than software applications/infrastructures. For example, let's suppose that if a software application goes down, it can be easily restored without significant impact, but if data becomes corrupted, it may have serious consequences. This is the exact reason why DataOps has taken longer to get off the ground compared to DevOps.
To ensure that data performs optimally and meets desired standards for quality, reliability, and efficiency, it is important to implement DataOps observability. This involves regularly observing and monitoring data and using the insights gained to make informed decisions. DataOps observability is a newer concept, but the practice of observability itself has a long history in the DevOps world. For example, observability platforms/solutions such as AppDynamics and Splunk help software engineers improve application reliability and reduce site/app downtime.
DataOps observability is not just limited to testing and monitoring data quality and the data pipeline. It also includes monitoring the health of the machine learning models, analyzing the application security measures to data infrastructure, tracking KPI and business monitoring. In other words, it covers a wide range of areas beyond just monitoring the health of data quality and data pipeline.
DataOps observability is a somewhat ambiguous concept that is interpreted differently in the data community. Still, in essence, it refers to an organization's/businesses’ ability to fully understand the health of the data. To sum it up, DataOps observability must address a few key areas: data quality and data pipeline reliability. Data quality is important to business users who want high-quality data they can trust. Data pipeline reliability is critical to data engineers and scientists, who need their data pipeline to run smoothly. Also, In addition to these two components, DataOps observability includes BizOps, which tracks/monitors the health and KPI of the business, as well as monitors the usage and the cost of the data. This is exactly where Chaos Genius fits in. Offering a complete observability solution, it facilitates businesses and organizations in testing the resilience and reliability of data, which can directly help businesses to improve their spending and boost their performance.

To create a successful data product, businesses should focus on three key areas: data governance, data access and security, and DataOps and quality.
Data governance involves understanding where the data comes from, while data access and security ensure that the data is being used in an appropriate and secure manner. Finally, DataOps and Quality involve automation, orchestration, CI/CD, configuration management and observability to ensure that the data product is high quality. The unification of these use cases is essential for the success of the data product.
In a nutshell, "DataOps Observability" refers to the ability to monitor and understand the various processes and systems involved in data management, with the main goal of ensuring the reliability, trustworthiness, and business value of the data. It involves monitoring and analyzing data pipelines, ensuring the quality of the data and demonstrating the business value of the data through metrics like financial and operational efficiency. DataOps observability allows businesses to improve the efficiency of their data management processes and make better use of their data assets. It helps to ensure that data is accurate, reliable, and easily accessible, enabling businesses and organizations to make data-driven decisions and drive business value.
Implementing DataOps
Implementing DataOps involves following a number of steps to ensure that data is collected, stored, and used in a way that supports business goals/objectives. This starts by identifying the data requirements and specifying the sources and types of data needed. A data governance framework is then established to ensure that data is collected, stored and used in a consistent and compliant manner. Data pipelines are designed and implemented to extract, transform, and load data from various sources into a centralized repository, and data quality checks and monitoring are put in place to ensure the accuracy, completeness and consistency of the data. To support a data-driven culture, it is crucial to build a collaborative and cross-functional team and establish a focus on data literacy, continuous improvement, and data-driven decision-making. Finally, it is important to continuously monitor and optimize the DataOps processes to improve efficiency, effectiveness, and agility.
List of Top DataOps tools and platforms available
One of the key components of DataOps is the use of specialized tools to manage and automate the flow of data. Tools can help with tasks such as scheduling and monitoring the execution of data pipelines, extracting, transforming and cleaning data, and integrating data from multiple different sources. There are various different DataOps tools available on the market, and the best choice will depend on your specific needs/requirements. Some tools are designed for general-purpose data integration and transformation, while others are more specialized for specific types of data or use cases. Here are some of the TOP Trending and Popular DataOps tools currently available on the market.
Apache Airflow:
Apache airflow is an open-source tool that is used for scheduling, monitoring and managing the execution of data pipelines. It provides a simple, intuitive interface for defining and organizing tasks, and it can be extended with custom plugins to support a wide range of data sources and destinations.

Databricks
Databricks is a cloud-based platform for data engineering, data science and AI/ML. It is built on top of the Apache Spark big data processing engine and offers a variety of tools for working with large amounts of data. Databricks' collaborative workspace is a great way for groups to collaborate on data projects together in real time. It provides a fully web-based notebook-like environment for writing and executing code, as well as data exploration and visualization tools. Databricks consist of connectors for common data sources and destinations, a library of pre-built transformations and functions, and support for different programming languages.

Snowflake
Snowflake is not a DataOps tool per se, it's a platform that can be used as a foundation for DataOps. Snowflake is a cloud-based data storage and analytics platform that is widely used for data warehousing, data lakes and data engineering. It is designed to handle the complexities of modern data management processes, such as data integration, data quality, data security, and data governance and to support a variety of data analytics applications, such as BI tools, ML and data science. Snowflake can also be used to manage the flow of data from various sources to the data warehouse, where it can be transformed, cleansed and optimized accordingly for analysis purposes. Snowflake’s architecture is designed to support high levels of concurrency, scalability and performance, making it well-suited for handling large amounts of data in real time. It also provides a number of features that supports data governance and security, such as data lineage, masking and auditing, which can be a very important consideration in DataOps environments.

Fivetran
Fivetran is also a cloud-based service that simplifies the process of transferring data between various sources and destinations(including Snowflake). It includes a range of connectors for popular data sources and destinations, including databases, cloud storage, SaaS applications—and more. One of the main features of Fivetran is its ability to support real-time synchronization and incremental updates, which means that it can continuously transfer new and updated data. This makes it ideal for use in scenarios where data needs to be kept up-to-date in near real-time. Fivetran has the ability to transfer data, but it also has a number of tools for managing and monitoring data pipelines. These tools include a web-based dashboard for tracking the status of data transfers and alerts for detecting issues and fixing 'em.

Talend
Talend is a commercial data integration platform that offers a wide range of tools for extracting, transforming, and loading (ETL) data. It includes an awesome and highly interactive graphical user interface (GUI) for building data pipelines and a library of pre-built connectors and transformations that can be used to integrate data from a wide range of sources and destinations. One of the main key features of Talend is its support for a wide range of data sources and destinations, including databases, cloud storage, SaaS applications—and more. It also includes support for popular programming languages, which allows users to write custom transformations and integrations. Talend also provides a range of tools for data governance, data quality, and data management, including support for tracking and managing data lineage.

Learn more about the Top DataOps tools available on the market in 2023.
Future of DataOps
DataOps is constantly evolving in response to emerging technologies and changing business needs. According to a report by MarketBiz, the global DataOps platform market is expected to experience significant growth over the forecast period of 2023 - 2032, with a projected value of $7,091.38 million. This growth is driven by the increasing demand for real-time data insights, the adoption of cloud-based solutions and the rising popularity of Agile and DevOps-related practices. The DataOps platform market is also anticipated to see growth in various regions, including North America, Europe, Asia Pacific, Latin America, the Middle East—and Africa. The market is projected to reach a value of $7,091.38 million, up from $1,150 million in 2022, with a compound annual growth rate of 22.4%.
The future of DataOps looks VERY bright with the current adoption of automation and artificial intelligence (AI). Automating data-related tasks and using AI/ML to analyze data allows businesses to reduce the time and resources needed for data management, leading to more efficient and accurate analysis. Another main key factor that will contribute to the future success of DataOps is the growing importance of data governance. As organizations collect and use more data, it is crucial to have proper controls in place to ensure data privacy/security. DataOps practices can help businesses establish and maintain effective data governance.
Overall, the future of DataOps is expected to see continued growth and evolution as businesses and organizations seek to optimize and leverage data-driven insights to drive their success.
DataOps in Action!
Previously, we discussed how Netflix uses DataOps to streamline its data management operations. To have a complete understanding of how DataOps is used in practice, let's examine a second case study. Suppose a leading online store/retailer decides to use DataOps to enhance their sales forecasting procedure. Previously, the retailer had difficulty making accurate sales forecasts due to the complexity of their data environment and the rigorous manual and laborious processes they had to go through to prepare and analyze data. To address these challenges, they formed a DataOps team that included data engineers, data scientists, and data/business analysts.
The team then implemented an automated data ingestion and transformation pipeline utilizing a market-leading data integration platform. This allowed them to swiftly and efficiently gather sales data from multiple sources, including online transactions, in-store purchases, user product preferences, user activity, and market research. The data was then cleaned, transformed, and validated using a series of predefined rules and procedures to ensure that it was ready for final analysis. The team then collaborated with data scientists to create and deploy AI/ML models that could predict future sales trends. These models were trained on historical product sales data and were designed to learn and adapt over time, becoming more accurate as more data was supplied to them. And after that, the team worked with data/business analysts to integrate the sales forecasting technique into the retailer's overall decision-making processes. This included making dashboards and reports that showed the outputs of the forecasting models and how they worked, as well as integrating the forecasts into the retailer's systems for managing product inventory and setting up product prices.
The results of the DataOps implementation were impressive. The store was able to track sales more accurately, which significantly improved managing the product inventory and aided in making smarter business decisions. Overall, the DataOps approach helped the retailer/store to make better understand and act on the data they had, leading to improved efficiency, accuracy, and agility.
Resources for learning more about DataOps
To learn more about DataOps, there are a number of resources available, including books, articles, online courses, videos and events/podcasts. Some recommendations(personal preference) includes:
Books:
“Creating a Data-Driven Enterprise with DataOps” by Ashish Thusoo and Joydeep Sen Sarma
"Practical DataOps: Delivering Agile Data Science at Scale" by Harvinder Atwal
“Data Teams: A Unified Management Model for Successful Data-Focused Teams” by Jesse Anderson
“Managing Data in Motion Data Integration Best Practice Techniques and Technologies” by April Reeve
“The DataOps Cookbook” by Christopher Bergh
Articles:
There are many articles available online that different cover aspects of DataOps.
Videos: There are several videos, online courses, and training courses available for those interested in learning more about DataOps.
Conclusion
DataOps is a crucial approach to data management operations that enables businesses to improve the speed, quality, and reliability of data processing and analysis. It facilitates collaboration and communication and accelerates the delivery of insights and results at a rapid pace. While implementing DataOps can present challenges, following best practices and communicating the benefits to stakeholders can help ensure a successful adoption. As emerging technologies continue to change the industry, we may anticipate DataOps to evolve and potentially expand into more fields. Above all, DataOps is a people-driven discipline, meaning that it depends on the abilities and knowledge of the individuals. It is not a tool or application that can be bought and implemented without the required human resources. Instead, it necessitates a team of proficient data experts that can collaborate effectively and efficiently.
References
[1] Swanson, Brittany-Marie. “What is DataOps? Everything You Need to Know.” Oracle Blogs, 12 March 2018, https://blogs.oracle.com/ai-and-datascience/post/what-is-dataops-everything-you-need-to-know. Accessed 7 January 2023.
[2] DataOps and the future of data management.” MIT Technology Review, 24 September 2019, https://www.technologyreview.com/2019/09/24/132897/dataops-and-the-future-of-data-management/. Accessed 6 January 2023.
[3] Valentine, Crystal, and William Merchan. “DataOps: An Agile Methodology for Data-Driven Organizations.” Oracle, https://www.oracle.com/a/ocom/docs/oracle-ds-data-ops-map-r.pdf. Accessed 6 January 2023.
[4] Anderson, C. (2019). Creating a Data-Driven Enterprise with DataOps. O'Reilly Media, Inc. Retrieved from https://www.oreilly.com/library/view/creating-a-data-driven/9781492049227/ Accessed 6 January 2023.
[5] A. Dyck, R. Penners and H. Lichter, "Towards Definitions for Release Engineering and DevOps," 2015 IEEE/ACM 3rd International Workshop on Release Engineering.
[6] Saurabh, Saket. “What is DataOps? | Platform for the Machine Learning Age.” Nexla, https://www.nexla.com/define-dataops/. Accessed 7 January 2023.
[7] Heudecker, Nick. “Hyping DataOps - Nick Heudecker.” Gartner Blog Network, 31 July 2018, https://blogs.gartner.com/nick-heudecker/hyping-dataops/. Accessed 7 January 2023.


